Clustering: It's Not Just For Indexers
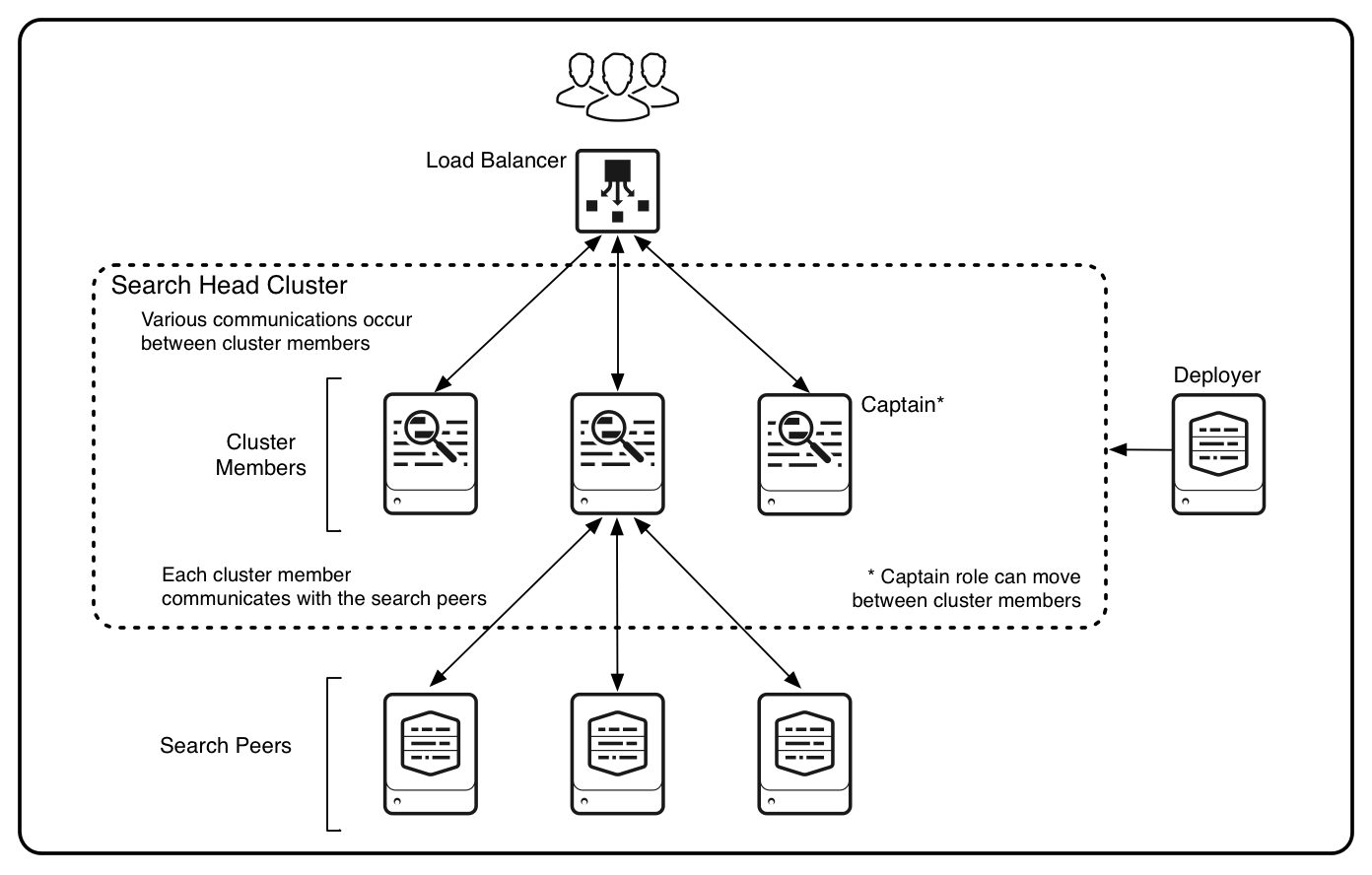
The release of Splunk Enterprise 6.2 introduced several great new features and enhancements. The new capabilities center around a new faster interface designed to assist with data onboarding, easier analytics and event pattern detection, and improved scalability and centralized management. While I would definitely recommend exploring the first two topics, this blog will focus on the latter. Core to the improvements in scalability and centralized management within Splunk Enterprise 6.2 is the introduction of Search Head Clustering. Search Head Clustering (SHC) is a direct replacement for the older feature (now deprecated in 6.2) called Search Head Pooling.
Search Head Pooling (SHP) was designed as a way to share apps, configurations and custom settings amongst search heads via an NFS share. The intended purpose of Search Head Pooling was to provide a clean and simple method of keeping multiple search heads configured the same so that front-end user access would be consistent no matter which search head they logged into. While this method did work for some smaller and less complex Splunk deployments, often there was significant performance impacts when scaling. The key reasons for the negative performance was due to poor IOPS to the NFS or network bandwidth and latency issues. The other major downfall of Search Head Pooling is that its implementation contains a single point of failure, the NFS share.
The Benefits
At its foundation a Search Head Cluster is simply a group of search heads. The members of the cluster are fundamentally the same and interchangeable. For this reason Splunk recommends that a load balancer be placed in front of the cluster so that it can balance the user load across all members of the cluster. The same searches, dashboards and apps are available on all search heads in the cluster. Here are the key benefits:
- Horizontal scaling: It is very simple to add another search head to the cluster should the need arise as search load or the number of users increases.
- High availability: When a member of the cluster becomes unavailable the users will not be impacted. The same searches, dashboards and apps will be available on any of the other available members.
- No single point of failure: All configurations are replicated among the members of the cluster. Search Head Clustering uses a dynamic captain to manage the cluster. If the captain goes down another member automatically takes its place.
- Job scheduling: The cluster also manages job scheduling. When a scheduled search needs to run, the cluster allocates the job to the optimal member (the member with the least load). This essentially eliminates the need for a dedicated job server.
- Configuration sharing: The cluster automatically replicates runtime updates to knowledge objects, such as dashboards, reports, alerts, and field extractions to all members.
- App management: Apps and certain other configurations are managed and pushed from a new Splunk instance called the deployer. The deployer is not a member of the cluster even though its duty is to deploy apps to the cluster members
Requirements
- Each member of the cluster must run on it’s own machine or virtual machine and must be running the same operation system. Currently Search Head Clustering is only available on Linux and Solaris operating systems.
- The same version of Splunk Enterprise must be running on all members of the cluster.
- The cluster must be running over a high-speed network.
- The cluster must contain three or more members.
The Captain
The captain of the cluster coordinates the main of actions taken within the cluster. The captain is also a normal member of the cluster and as such performs all common search activities. Any member can perform the role of captain, but the cluster has just one captain at any time. When the cluster is initially brought online one member of the cluster is assigned the role of the captain. Over time, if failures occur, the captain changes and a different member will be elected to the role. The captain’s responsibilities include the following:
- Scheduling of jobs based on relative current loads.
- Coordination of alerts.
- Pushing of knowledge bundles to search peers (indexers).
- Coordination of search artifact replication.
- Replication of configuration updates.
For more information about the captain see the official Splunk documentation: http://docs.splunk.com/Documentation/Splunk/latest/DistSearch/SHCarchitecture#Search_head_cluster_captain
The Deployer
The deployer is the Splunk instance that distributes apps and certain specific configuration files to the members of the cluster. The deployer distributes the apps in response to a CLI command and also to any new member that joins the cluster. Essentially, the deployer can be thought of as a Deployment Server designed specifically for Search Head Clustering. Each of the members of the cluster is told the location of the deployer either during initialization time or via an edit to server.conf.
For more information regarding the deployer see the Splunk official documentation: http://docs.splunk.com/Documentation/Splunk/latest/DistSearch/PropagateSHCconfigurationchanges
Deployment Steps
- Identify your requirements. Determine the size of the cluster and the replication factor that you want to implement.
- Set up the deployer.
- Initialize the cluster members.
- Bootstrap the cluster captain.
- Perform post-deployment set-up.
For more information regarding deployment and initialization of Search Head Clustering see the Splunk official documentation: http://docs.splunk.com/Documentation/Splunk/latest/DistSearch/SHCdeploymentoverview
As always, thank you for reading and should you have any questions or would like some assistance with your deployment of Search Head Clustering please do not hesitate to contact us at info@function1.com.
Credits: Header image from splunk.com
- Log in to post comments

{kind=link}