Why Solr?
By: Hani March 03, 2015




When it comes to setting-up search for a Drupal site, out-of-the-box Drupal comes with a primitive built-in search engine. The out-of-the-box search engine can be sufficient if we are running a Content Management System (CMS) for a small blogging site. There are some basic customization and ranking settings that can be tailored; e.g. add more weight to blogs with more comments or recently submitted blogs or content. And it is neat because Drupal search respects node access permissions.
But not all Drupal installs are for blogging purposes. Some are used for eCommerce or perhaps just more intricate such as mollom.com For such sites, Drupal’s core search engine will neither deliver the scalability and fault tolerance nor the needed advanced search capabilities; it’s just isn’t designed for such requirements. Hence, Solr. Solr is an open source enterprise search platform built with Java and has inherent robust features that make it a strong candidate for enterprise Drupal sites. It's features include:
- Built around the well-established Lucine framework designed for indexing and search technology.
- Elastically scalable as the number of cores/indexes can grow and shrink as needed.
- Can indexes binary documents (Docs, PDFs. PPTs, etc.) along with Drupal nodes.
- Optimized for high traffic sites.
- Includes advanced search capabilities, e.g. joins cross data types, grouping, spatial search, faceting, highlighting, etc.
- Written in Java - platform independent.
- It integrates with other technologies beside Drupal; e.g. Ruby on Rails
- It has XML/HTTP and JSON/Python/Ruby APIs.
Setting up a Solr server is pretty straightforward: the download is here and the installation instructions are here. But as far as wiring Solr to Drupal, we need to make a decision in terms of which module to use: either Apache Solr or Search API and that really depends upon the search requirements as each integration point has compelling use cases. But for the most part, the install base for the later module by far exceeds the former moreover the Drupal community is more actively engaged in maintaining the Search API module. In my view, I think both modules overlap in functionality and provide excellent faceting though my preference is Search API because of its rich extension modules that cover an array of search functionalities. But aside from deciding on which Drupal to Solr integration module, there is some upfront legwork that needs to be done to provide for a successful search solution and that is the provision of a strong taxonomy and the appropriate tagging of content in order to leverage the power of facets in searching.
Faceted search is the application of dynamic filters while searching content. The classic example is Amazon. Type “The Hobbit” in the search box at amazon.com and Amazon starts to guess where we are looking for that item: perhaps in books, movies, toys, etc.
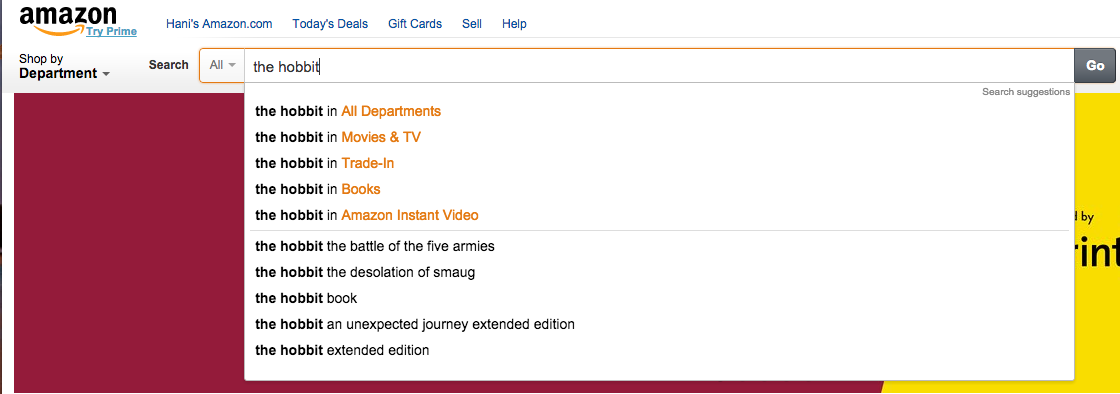
and then as we select the relevant department, Amazon begins to list the different facets (search filters) for “The Hobbit” in the selected department. For movies, it would be: format, release date, actors, etc. whereas for books, it would be: books genre, format, author, release year, etc.
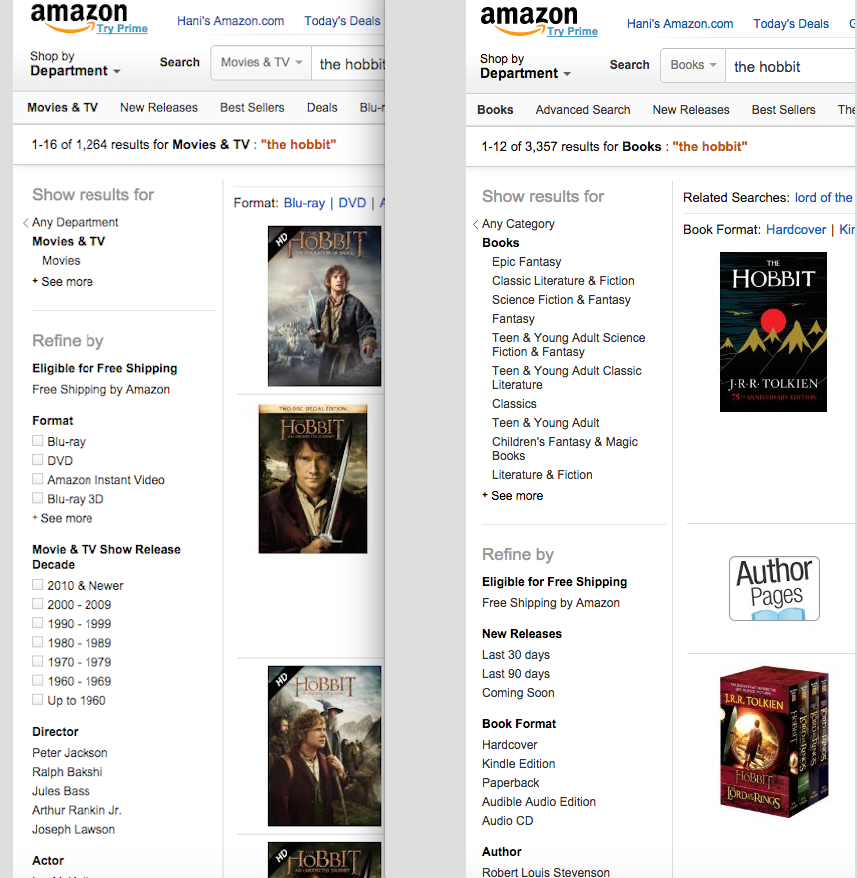
Correlating the amazon.com example to the Drupal world, the analogy can be that Amazon’s concept of “Departments” is analogous to a Drupal taxonomy attribute. As we know, in the Drupal world content is classified by type and each content type has an array of fields and a taxonomy vocabulary. Without the proper taxonomy vocabulary/vocabularies and a meaningful list of terms in each vocabulary, faceting becomes meaningless and just unbeneficial.
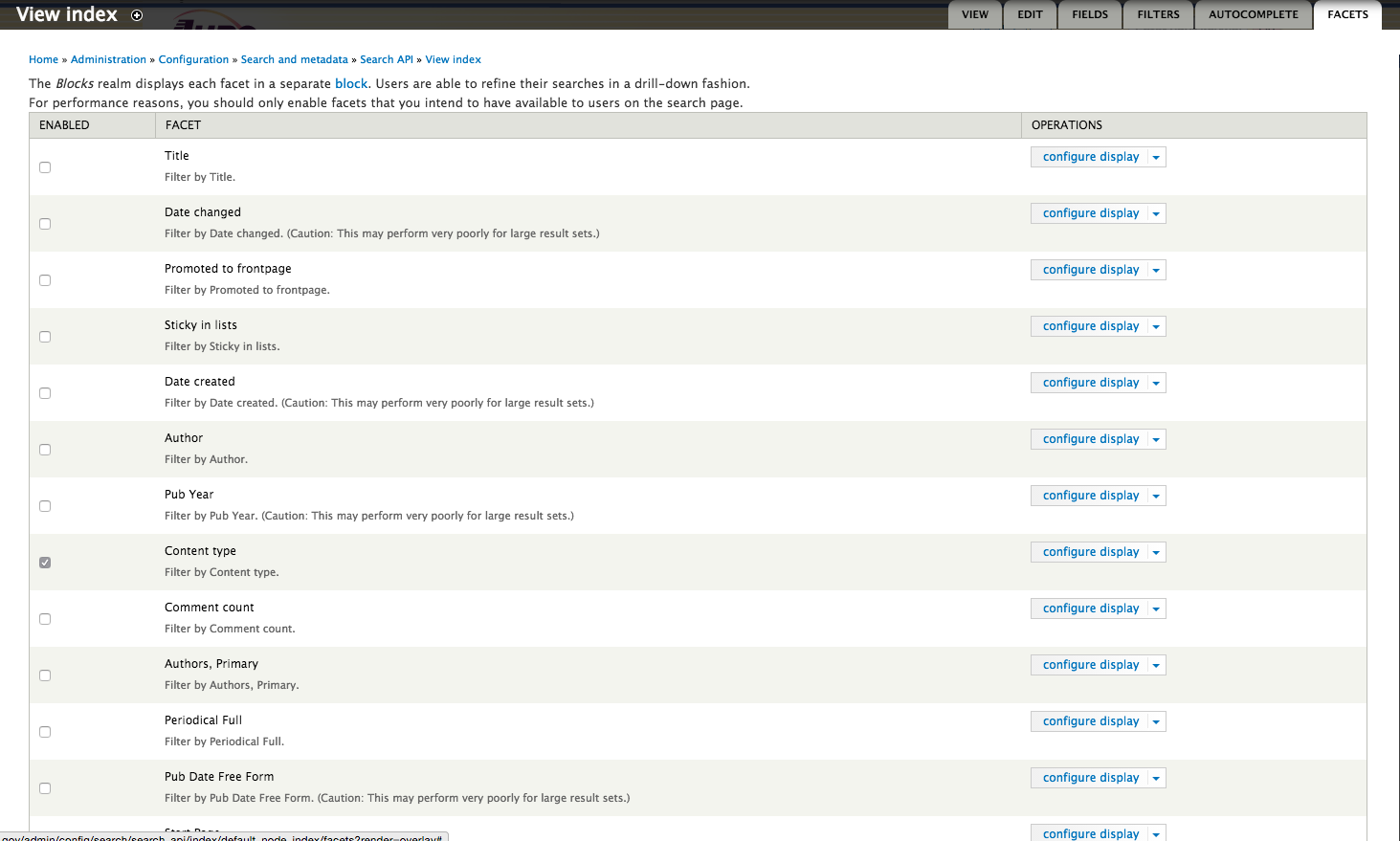
Amazon isn’t using Solr but mollom.com is a Drupal site that uses Solr. If we search for WordPress in mollon.com Solr will return the “Filter by Type” and “Filter by Platform” facets and few sort options. To configure such a facet using the Search API and Facet API modules, under the "Search API" configuration page, select the "Facets" tab and enable the fields that you will need to filter or facet on; e.g. type, date, author, taxonomy, etc.
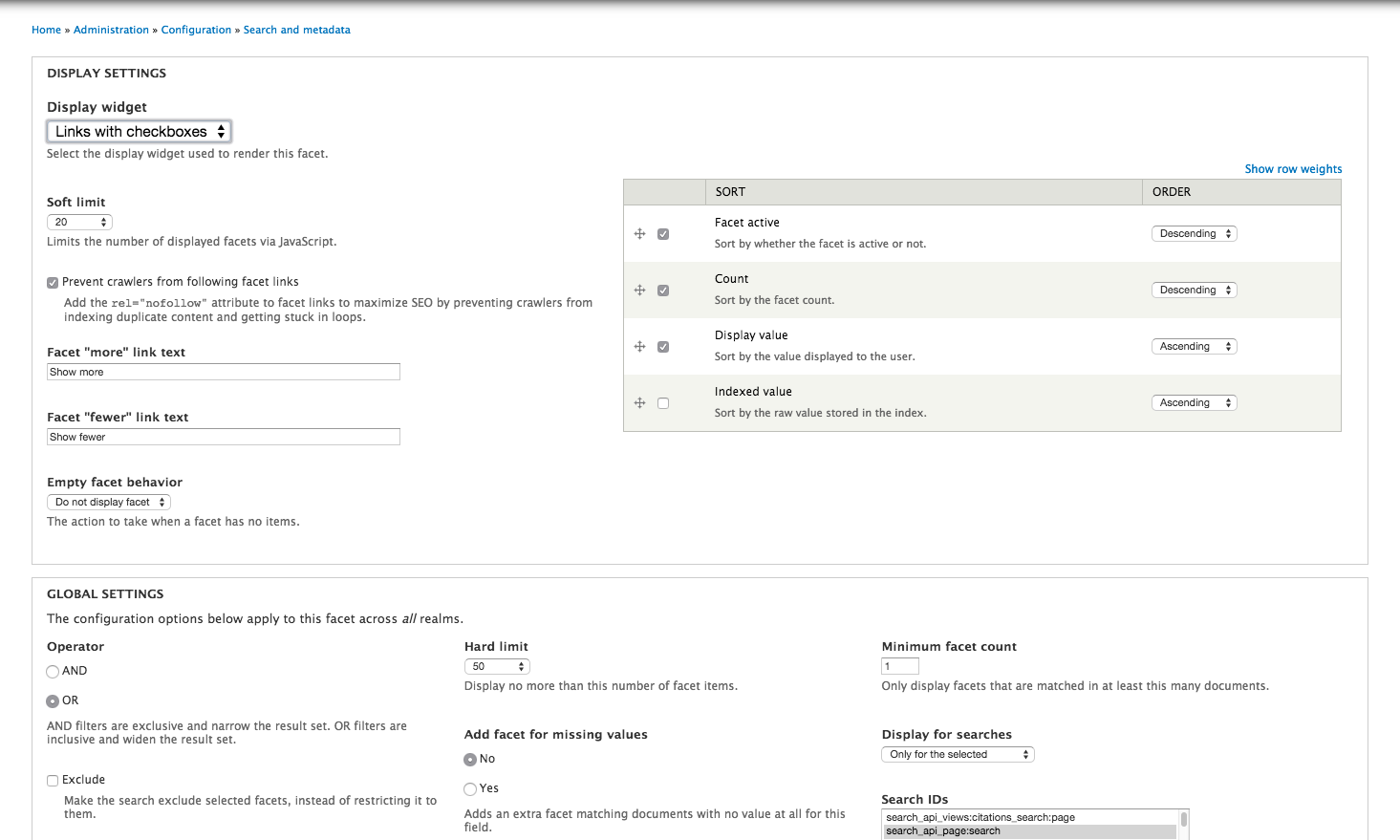
We can further configure each facet, e.g. the display widget, minimum facet count, ascending or decending order, etc.
Lastly, place the facets blocks in the appropriate regions in the template.
But really, all of this is straightforward and mechanical as the Search API and the Facet API modules are doing all the work. The lesson learnt here is that unless you are faceting on basic content fields: e.g. content type, author, and date the exercise is pretty simple. But for complex content types, e.g. a book for a library site or a course catalog for a college site, a carefully planned, structured, and thought out taxonomy is just crucial.
- Log in to post comments
