Splunk Multisite Clustering
Splunk 6.1 – Introducing Multisite Clustering
With the release of Splunk Enterprise 6.1 have come many new features and enhancements. The initial reaction may be to question if upgrading to the new version is truly worth the effort. In this post I will describe one of the great new features in Splunk 6.1 that may turn your answer to that question into an unequivocal “yes”.
Introducing multisite clustering
First, allow me to propose a conundrum that many Splunk administrators within multi-site organizations may have already encountered. Your Splunk deployment incorporates data from various physical sites. This data needs to be searchable by Splunk users regardless of their location. As the Splunk administrator, you are looking for a way to efficiently distribute the Splunk server infrastructure (Search Heads and Indexers) while still providing access to all of the data over multiple locations without significantly impacting search performance. You would also like to keep cross-site network traffic to a minimum.
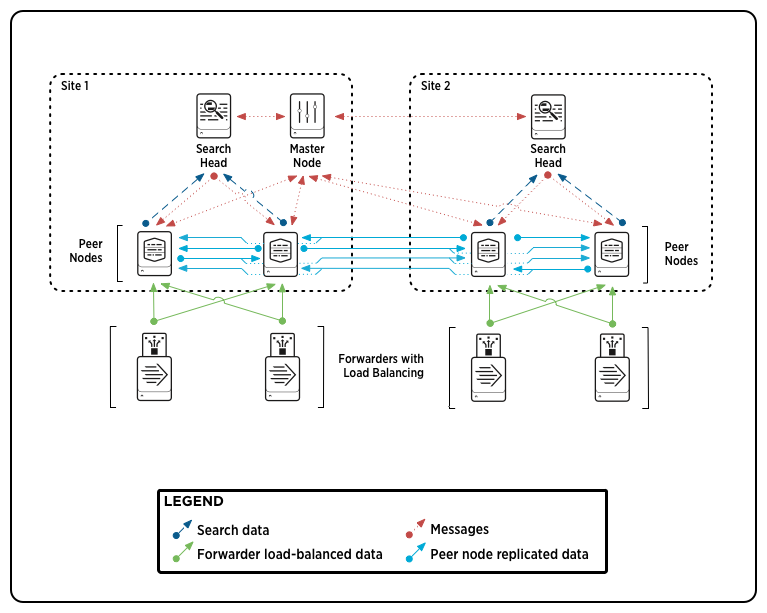
Up until now the configuration of indexer clustering and cross-site replication of data has been a complex and difficult endeavor. With the new release of Splunk Enterprise 6.1, clusters now have a built-in site-awareness. This means that for each major location or site in your organization you can explicitly configure a distinct cluster of search peers to have their own search head(s). This simplifies and extends the ability to implement a cluster that spans multiple physical sites, such as data centers, thus enhancing the disaster recovery capabilities of the cluster.
Implement multisite search affinity
One of the key benefits of multisite clustering is that it allows you to configure a cluster so that search heads perform their searches only on data stored on their local sites. This reduces network traffic while still providing access to the entire set of data, because each site contains a full copy of the data. This benefit is known as "search affinity."
For example, let’s say you have two data centers in different states. One of the data centers is in Pennsylvania and the other is in New York. You set up a two-site cluster, with each site corresponding to a data center. Search affinity allows you to reduce long-distance network traffic. Search heads at the Pennsylvania data center search only the peers (indexers) within the Pennsylvania data center, while search heads in New York search only their local New York data center peers.
Configuration via server.conf
Like most features within Splunk, multisite clustering can be configured in various ways. A link to the official documentation for configuring via the CLI can be found here.
Much like configuration within a single-site cluster, the configuration of multisite clustering is performed within the server.conf. There are several new attributes that are now used to define clustering of the multiple sites.
Example master node
You configure the key attributes for the entire cluster on the mater node. Here is an example of a multisite configuration for a master node:
[general] site = site1 [clustering] mode = master multisite = true available_sites = site1, site2 site_replication_factor = origin:2, total:3 site_search_factor = origin:1,total:2 pass4SymmKey = whatever
Example peer node
To configure a peer node in a multisite cluster, you set a site attribute in the [general] stanza. All other configuration settings are identical to a peer in a single-site cluster. Here is an example configuration for a multisite peer node:
[general] site = site1 [replication_port://9887] [clustering] master_uri = https://10.152.31.202:8089 mode = slave pass4SymmKey = whatever
Example search head
[general] site = site1 [clustering] multisite = true master_uri = https://10.152.31.202:8089 mode = seachhead pass4SymmKey = whatever
The official documentation from Splunk is available at Multisite Deployment Overview. As always, please feel free to leave comments or questions below.
Happy Splunking!
- Log in to post comments
